Linux Boot flow
The flow chart below shows the various stages during the booting of Linux and lists some of the major
parts of each of these steps.
parts of each of these steps.

Module to display the current working directory
The following module, on insertion into the kernel, displays the current working directory in the kernel space . The code is same as what is used in the system call getcwd.
The current working directory is saved as the member, name, of the structure qstr, which in turn is a member, d_name, of the structure dentry. Both the structures are found in dacache.h.
The pointer to the dentry is stored as a member, dentry, of the structure path which is defined in the file path.h
The file fs_struct.h defines a structure by the name fs_struct which has members,path and root, of type struct path.
The current pointer is of the type struct task_struct, this structure is defined in sched.h and the structure has a member fs of the type fs_struct.
Hence to access the value of the current working directory we need to trace the path
fs->path->dentry->d_name->name
*************************current_pwd.c**********************************
#include <linux/init.h>
#include <linux/module.h>
#include<linux/sched.h>
#include <linux/rcupdate.h>
#include <linux/fdtable.h>
#include <linux/fs.h>
#include <linux/fs_struct.h>
#include <linux/dcache.h>
MODULE_LICENSE("Dual BSD/GPL");
static int current_init(void)
{
char *cwd;
struct path pwd, root;
pwd = current->fs->pwd;
path_get(&pwd);
root= current->fs->root;
path_get(&root);
char *buf = (char *)kmalloc(GFP_KERNEL,100*sizeof(char));
cwd = d_path(&pwd,buf,100*sizeof(char));
printk(KERN_ALERT "Hello,the current working directory is \n %s",cwd);
return 0;
}
static void current_exit(void)
{
printk(KERN_ALERT "Goodbye cruel world");
}
module_init(current_init);
module_exit(current_exit);
***********************************************************************************
****************************Makefile*****************************
obj-m += current_pwd.o
all:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules
clean:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean
**************************************************************
Run the followig commands to compile and load.
$ sudo make
If there are no errors after compiling in the above step, we can insert the module using
$ sudo insmod current_pwd.ko
To see the output
$ dmesg
At the end of the messages you should see your current working directory being printed .
Send output from one terminal to another
If you are running a program in one terminal and want to view its output in another, here is a simple way to do it.
Open the the terminal in which you want to view the output
Run the command "tty"
The output should be some thing like "/dev/pts/<Number>" Note this down
Now open the terminal in which you want to execute the program and execute it, redirecting the output to the path that you got as the output to the "tty" command
for eg :
./test > /dev/pts/3
The output will appear in the other terminal instead of the one in which you are executing the program.
Open the the terminal in which you want to view the output
Run the command "tty"
The output should be some thing like "/dev/pts/<Number>" Note this down
Now open the terminal in which you want to execute the program and execute it, redirecting the output to the path that you got as the output to the "tty" command
for eg :
./test > /dev/pts/3
The output will appear in the other terminal instead of the one in which you are executing the program.
KVM introduction
KVM Introduction : 1
KVM which stands for kernel based virtualization is a linux kernel combined with the kvm kernel module tranforms the usual linux kernel into a bare metal hypervisor. Once KVM is installed into the kernel we can create Virtual machines in it and control them using various user space tools like qemu,libvirt or virsh.
Virtualizations Involves
CPU Virtualization
Memory Virtualization
I/O Virtualization
CPU Virtualization : To virtualize the CPU, KVM makes use of the hardware solution, that is CPUs which have virtualization instructions built into them . Intel calls this VT-X and AMD calls it AMD-V. The traditional architecture of CPUs had the standard ring based opertion as shown below.

The Operating system would execute the privileged instructions in the ring 0 and the user space applications would execute in the ring 3. The introduction of virtualization required that a new layer be present between the hardware and the operating system. This could have been achieved in two ways
0/1/3 model where the operating system is moved to the ring 1 and hypervisor is executed in the ring 0
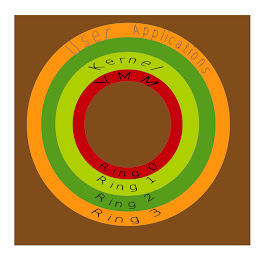 0/3/3 model where the operating system and applications are both executed in the ring3 and the hypervisor executes in the ring 0.
0/3/3 model where the operating system and applications are both executed in the ring3 and the hypervisor executes in the ring 0.

Both these models move the operating system away from ring 0 leads to multiple problems because the operating system designed to always execute in ring 0. The software solutions like Binary translation and paravirtualization try to address the problems because of this change in the ring of operation of the operating system. The hardware solution introduced by Intel and AMD-V solve this by introducing new modes of operation in the CPU.
The intel Virtualization enabled hardare have new modes of operation VMX Root and VMX non root. The VMX root operation is used to execute the hypervisor and the VMX non root operation is used to execute the VM itself. Each of these modes of CPU have ring 0,1,2,3.
 Thus the operating system can continue to operate in ring0 in VMX non root mode and thus retain all its control over the hardware just as a traditional opertaing systems. The hypervisor on the other hand executes in ring 0 in the VMX root mode. Thus even the hypervisor get the complete control of the hardware by being present in the ring0. But at any given time either othe VM or the hypervisor would be operating in the ring 0 mode.
This takes care of a number of problems that exist in the software solutions of virtualization and also make the virtualization to be much quicker as the VM is able to operate on the hardware directly with out any intervention by the hypervisor during the normal operation. The control shifts out of the VM only on a I/O which is handled by the user space application running in the host kernel and interrupts or any other signals which are handled by the hypervisor.
Thus the operating system can continue to operate in ring0 in VMX non root mode and thus retain all its control over the hardware just as a traditional opertaing systems. The hypervisor on the other hand executes in ring 0 in the VMX root mode. Thus even the hypervisor get the complete control of the hardware by being present in the ring0. But at any given time either othe VM or the hypervisor would be operating in the ring 0 mode.
This takes care of a number of problems that exist in the software solutions of virtualization and also make the virtualization to be much quicker as the VM is able to operate on the hardware directly with out any intervention by the hypervisor during the normal operation. The control shifts out of the VM only on a I/O which is handled by the user space application running in the host kernel and interrupts or any other signals which are handled by the hypervisor.
KVM makes use of this hardware feature while running the virtual machines. Thus other than the traditional kernel space and user space there exits a new mode called as the guest mode of operation in the kernel. The VM opertes in this guest mode which makes use of the VMX non root mode. The guest OS works in the ring 0 of the VMX non root mode and the applications in the guest OS in the ring 3 of the VMX non root mode The KVM kernel on the other hand works in the ring 0 of the VMX root mode.
and the kernel which acts as the hypervisor executes in the kernel space of the vmx root mode.
CPU Virtualization
Memory Virtualization
I/O Virtualization
CPU Virtualization : To virtualize the CPU, KVM makes use of the hardware solution, that is CPUs which have virtualization instructions built into them . Intel calls this VT-X and AMD calls it AMD-V. The traditional architecture of CPUs had the standard ring based opertion as shown below.



Both these models move the operating system away from ring 0 leads to multiple problems because the operating system designed to always execute in ring 0. The software solutions like Binary translation and paravirtualization try to address the problems because of this change in the ring of operation of the operating system. The hardware solution introduced by Intel and AMD-V solve this by introducing new modes of operation in the CPU.
The intel Virtualization enabled hardare have new modes of operation VMX Root and VMX non root. The VMX root operation is used to execute the hypervisor and the VMX non root operation is used to execute the VM itself. Each of these modes of CPU have ring 0,1,2,3.

KVM makes use of this hardware feature while running the virtual machines. Thus other than the traditional kernel space and user space there exits a new mode called as the guest mode of operation in the kernel. The VM opertes in this guest mode which makes use of the VMX non root mode. The guest OS works in the ring 0 of the VMX non root mode and the applications in the guest OS in the ring 3 of the VMX non root mode The KVM kernel on the other hand works in the ring 0 of the VMX root mode.
and the kernel which acts as the hypervisor executes in the kernel space of the vmx root mode.
Linux Kernel Programming Quiz
Linux Kernel Quiz
This is a quiz on basics of linux kernel programming.Linux Quiz 1
A quiz on linux Basics
This is a quiz on basics of linux, have fun.... Answers to quiz can be found at : Answers to linux quiz-1Atomic Variables
With the advent of multiprocessor systems, the requirement of the programs to maintain the synchronization has become mandatory.
In a multiprocessor systems if a program is being executed on multiple processors with data being shared between the processors then the update of data by one one processor might be affected by an update by another processor.
For eg consider the instruction val = val + 1; This is a good example of a read modify write instruction where the processor read the value of "val" modifies it and write it back. In a uniproessor system this poses no problem because the processor will not let go of the memory bus until the instruction is not completely executed.
But in a multiprocessor system, the memory bus might be released after the read and while one processor updates the value another processor can make use of the bus.
If two processors, processor A and processor B reach this instruction at the same time. Assume the value of val is 3 initially.
Processor A reads the value 3 and lets go of the bus
While processor A updates the val processor B also reads val as 3 and lets the go of the bus
Now processor A updates the new value 4 in the val
Then processor B also updates the value of val as 4.
With 2 increments the value of val should have become 5, but it remains at 4 because both the processors were allowed to read the variable before one of them finished the operation on it.
This simultaneous access can be prevented using semaphores and spinlocks but implementing a semaphore or spinlock for one instruction might be an overkill.
There is another solution in linux kernel called atomic variables.
Atomic variables are the ones on whom the read modify write operation is done as one instruction with out any interruption .
In the above example if val was an atomic variable then processor B would have been allowed access to the variable only after processor A has finished the updating the visible, until then the processor A would have held on to the memory bus.
To make use of the atomic variables the variable needs to be declared as of type atomic_t.
The access to the atomic variables is not through the standard instructions but using special functions listed below.
atomic_t *val Declaration
atomic_read(val): Returns the value of *val
atomic_set(val,i) : Sets *val to i
atomic_add(i,val): adds i to *val
atomic_sub(i,val): Subtracts i from *val
atomic_sub_and_test(i, val) : Subtracts i from *val and returns 1 if the result is zero,
atomic_inc(val) : Adds 1 to *val
atomic_dec(val) : Subtracts 1 from *val
atomic_dec_and_test(val): Subtracts 1 from *val and returns 1 if the result is zero, otherwise it returns 0
atomic_inc_and_test(val): Adds 1 to *v and returns 1 if the result is zero; 0 otherwise
atomic_add_negative(i, val): Adds i to *val and returns 1 if the result is negative, otherwise it returns 0
atomic_inc_return(val): Adds 1 to *val and returns the new value of *val
atomic_dec_return(val): Subtracts 1 from *val and return the new value of *val
atomic_add_return(i, val) : Adds i to *val and returns the new value of *val
atomic_sub_return(i, val): Subtracts i from *val and return the new value of *val
Let us write a small module using one of the functions and see how it gets implemented at the assembly level.
***********************test_atomic.c **********************
#include<linux/kernel.h>
#include<linux/module.h>
atomic_t *test;
int test_init(void)
{
atomic_set(test,2);
atomic_add(2,test);
}
void test_exit(void)
{
}
module_init(test_init);
module_exit(test_exit);
**************************************************************
Save the above code as test_atomic.c, the makefile required to compile the code will be
*****************Makefile*******************************
ifneq ($(KERNELRELEASE),)
obj-m := test_atomic.o
else
KERNELDIR ?= /lib/modules/$(shell uname -r)/build
PWD := $(shell pwd)
default:
$(MAKE) -C $(KERNELDIR) M=$(PWD) modules
clean:
$(MAKE) -C $(KERNELDIR) M=$(PWD) clean
endif
********************************************************
Now compile the code by running the command make
$ make
This should generate the file test_atomic.ko.
To look at the assembly instructions for this code we can use "objdump" which is a command to read information from object files.
Run the command as follows
$ objdump -d -S test_atomic.ko
test_atomic.o: file format elf32-i386
Disassembly of section .text:
00000000 <init_module>:
0: a1 00 00 00 00 mov 0x0,%eax
5: c7 00 02 00 00 00 movl $0x2,(%eax)
b: a1 00 00 00 00 mov 0x0,%eax
10: f0 83 00 02 lock addl $0x2,(%eax)
14: c3 ret
00000015 <cleanup_module>:
15: c3 ret
The lines after <init_module> in the output of the command is the assembly code for the init function we have written.
If we look at the 4th line of the assebly instructions we notice an instruction that starts with the keyword "lock" and then followed by "addl".
This instruction corresponds to the function "atomic_add". The lock keyword makes sure that the memory bus remains locked as long as the variable is not read modified and written back.
Similarly any of the atomic instructions are executed with the lock keyword making sure that the read modify write happens with out any interruptions.
VI editor tips for programmers - 3
In this post we will look at a few settings that are useful while programming.
Syntax coloring
While typing a program, it is always helpful if various colors are used to higlight different keywords and variables of a program. This
can be acheived by running the command
:syntax on
While in the command mode in the vi editor.
The screenshots below show the difference.
With out syntax highlighting

With syntax highlighting

Without numbering
With Numbering and syntax enabled.

Line numbers
A line number can be added to every line in the file by running the command
:set nu
or
:set number
The screenshots below depict the working of this command
VI editor tips for programmers -2
Playing around with line numbers
In the last post, VI editor tips for programmers -1 , we saw how VI editor helps in keeping track of the braces in a program.
In this post let us look at a few tips that relate to line numbers in a program.
Very often a compilation error points out to a line where some thing is wrong for eg :
*****************hello.c****************
#include<stdio.h>
main ()
{
printf("Hello world");
if(1) {
printf("Hello again"));
}
else {
printf("Hello once more");
}
}
****************************************
If we compile the above program using gcc compiler as follows
$ cc hello.c
We get the error
test.c: In function ‘main’:
test.c:6: error: expected ‘;’ before ‘)’ token
test.c:6: error: expected statement before ‘)’ token
The error thrown also speciifes the line number in which there is possible error. From the above error we know there might be an error in the line no 6.
Now open the file using vi
$ vi test.c
To go to the sixth line we could either move with the arrow keys looking at the bottom right of the editor for the line numbers being displayed.
But if the code is too big and error is 100th or the 1000th line then just using arrow keys of pgup, pgdwn keys are not convienient.
To move to any line number in the file directly , go to command mode (by pressing esc) and type
:"number"
That is in our case, to go to the 6th line we will have to type
:6
and press enter. The cursor should automaticlly move to the sixth line.
Another way of doing this is to pass the line number while opening the file itself .
$ vi test.c +6
The file opens with the cursor directly placed at the sixth line.
Moving with in the file by specific number of lines can also be done with out using the arrow keys.
To move two lines above/before the current line just do the following in the command mode
:-2
To move by two lines below/after the current line
:+2
Hope the tips makes programming and debugging much easier.
In the last post, VI editor tips for programmers -1 , we saw how VI editor helps in keeping track of the braces in a program.
In this post let us look at a few tips that relate to line numbers in a program.
Very often a compilation error points out to a line where some thing is wrong for eg :
*****************hello.c****************
#include<stdio.h>
main ()
{
printf("Hello world");
if(1) {
printf("Hello again"));
}
else {
printf("Hello once more");
}
}
****************************************
If we compile the above program using gcc compiler as follows
$ cc hello.c
We get the error
test.c: In function ‘main’:
test.c:6: error: expected ‘;’ before ‘)’ token
test.c:6: error: expected statement before ‘)’ token
The error thrown also speciifes the line number in which there is possible error. From the above error we know there might be an error in the line no 6.
Now open the file using vi
$ vi test.c
To go to the sixth line we could either move with the arrow keys looking at the bottom right of the editor for the line numbers being displayed.
But if the code is too big and error is 100th or the 1000th line then just using arrow keys of pgup, pgdwn keys are not convienient.
To move to any line number in the file directly , go to command mode (by pressing esc) and type
:"number"
That is in our case, to go to the 6th line we will have to type
:6
and press enter. The cursor should automaticlly move to the sixth line.
Another way of doing this is to pass the line number while opening the file itself .
$ vi test.c +6
The file opens with the cursor directly placed at the sixth line.
Moving with in the file by specific number of lines can also be done with out using the arrow keys.
To move two lines above/before the current line just do the following in the command mode
:-2
To move by two lines below/after the current line
:+2
Hope the tips makes programming and debugging much easier.
Vi editor tips for programmers-1
A series of posts describing tips helpful for programmers who use VI editor.
Finding matching braces in a program
The common error that comes across during programming in any language is mismatching braces. vi gives an easy way to track the matching
brace for each closing or opening brace.
For eg:
**********test.c**************
#include<stdio.h>
main ()
{
printf("Hello world");
}
***************************
Open a vi editor and type the above program (or any program) into it and save it as test.c.
Move the cursor to the closing brace } and hit the % key. The cursur will auotmatically move to the corresponding openging brace .
Now try this one
*******************test.c******************
#include<stdio.h>
main ()
{
printf("Hello world"));
}
******************************************
In the above program we have added an extra closing ")" bracket for the printf function call. Move the cursor to the second closing bracket and
hit "%". You will notice that the cursor does not move any where as it does not find the matching closing brace.
Let us look at one more example with a few more braces
******************test.c**********************
#include<stdio.h>
main ()
{
printf("Hello world");
if(1) {
printf("Hello again");
}
else {
printf("Hello once more");
}
}
}
************************************************
Let us start by matching the opening brace this time. Move the cursor to first curly brace "{" and press "%". The cursor will move to the closing brace "}" just above the final closing brace, which makes it obvious that one brace is extra in the code, thus we can remove the final curly brace to correct the program.
In the next post we will look at a few tips related to line numbers in the "vi" editor.
~
Finding matching braces in a program
The common error that comes across during programming in any language is mismatching braces. vi gives an easy way to track the matching
brace for each closing or opening brace.
For eg:
**********test.c**************
#include<stdio.h>
main ()
{
printf("Hello world");
}
***************************
Open a vi editor and type the above program (or any program) into it and save it as test.c.
Move the cursor to the closing brace } and hit the % key. The cursur will auotmatically move to the corresponding openging brace .
Now try this one
*******************test.c******************
#include<stdio.h>
main ()
{
printf("Hello world"));
}
******************************************
In the above program we have added an extra closing ")" bracket for the printf function call. Move the cursor to the second closing bracket and
hit "%". You will notice that the cursor does not move any where as it does not find the matching closing brace.
Let us look at one more example with a few more braces
******************test.c**********************
#include<stdio.h>
main ()
{
printf("Hello world");
if(1) {
printf("Hello again");
}
else {
printf("Hello once more");
}
}
}
************************************************
Let us start by matching the opening brace this time. Move the cursor to first curly brace "{" and press "%". The cursor will move to the closing brace "}" just above the final closing brace, which makes it obvious that one brace is extra in the code, thus we can remove the final curly brace to correct the program.
In the next post we will look at a few tips related to line numbers in the "vi" editor.
~
Difference between tasklet and workqueue
In the last few posts we saw the basics of tasklets and workqueues with examples. Both tasklet and workqueue are used for similar purposes, but they are not the same and can not be used instead of each other. Let us look at the differences between them.
This is biggest difference between the two :
A tasklet always runs in the interrupt context, that means when a tasklet executes it is as if the processor is executing an interrupt service routine.
Thus while executing a tasklet a task can not got to sleep or can not hold a semaphore as neither of them are allowed while in a interrupt service routine.
On the other hand a workqueue executes as a normal process and not a interrupt, hence a worqueue can go to sleep it can hold semaphores.
The above difference will help in deciding when should a tasklet be used and when should a workqueue be used. To see this difference practically we will make use of a function "in_interrupt() ". When called, the function returns true if the task is executing as an interrupt i.e. in interrupt context else it returns false.
We will add this function call to the exaples of tasklet_init and workqueue_runtime and try to find out if tasklet runs in a interrupt context or not.
We only need to modify the tasklet and workqueue functions from the previous example and here are the modified functions
tasklet : Modified task_fn
void task_fn(unsigned long arg)
{
printk(KERN_INFO "In tasklet function");
if(in_interrupt())
printk(KERN_INFO "Running as an interrupt");
else
printk(KERN_INFO "Running as a process");
printk(KERN_INFO "\n The state is %d",task->state);
printk(KERN_INFO "\n The count is %d",task->count);
}
workqueue: Modified work_fn
void workq_fn(unsigned long arg)
{
if(in_interrupt())
printk(KERN_INFO "Running as an interrupt");
else
printk(KERN_INFO "Running as a process");
atomic_long_set(&(workq->data),10);
printk(KERN_INFO "In workq function %u",atomic_long_read(&(workq->data)));
}
Modify the tasklet_init.c and workq_runtime.c as shown above. Compile and insert both the modules . If there are no errors in compiling and inserting
we can see the difference betwee the tasklet and worqueue as follows
$ cat /proc/initask
$ dmesg | tail -6
In proc initask
In tasklet function
Running as an interrupt
The state is 2
The count is 0
$ cat /proc/sched_work
$ demsg | tail -4
In proc sched workq
Running as a processIn workq function 10
As we can see in the above output, when we run the tasklet we see that the task is running in the interrupt context and when we run the task in a workqueue it does not run as a interrupt but as a process.
Finding vendor id and product id of a usb device
Every usb device that we plug into a system has a vendo id and a product id that uniquely identifies the device. The vendor id is given by the usb.org to the vendor who in turn assigns unique product id to the products they manufacture. The kernel uses these product id and vendor id to find out if the driver supports the device or not.
To find the vendor id and product id of a device we can use the command "usb-devices" . The command lists out details of all the usb busses in the system and if any device is connected to any of the bus, it gives information of that device.
For eg:
$ usb-devices
T: Bus=01 Lev=00 Prnt=00 Port=00 Cnt=00 Dev#= 1 Spd=480 MxCh= 6
D: Ver= 2.00 Cls=09(hub ) Sub=00 Prot=00 MxPS=64 #Cfgs= 1
P: Vendor=1d6b ProdID=0002 Rev=02.06
S: Manufacturer=Linux 2.6.32-5-686 ehci_hcd
S: Product=EHCI Host Controller
S: SerialNumber=0000:00:02.2
C: #Ifs= 1 Cfg#= 1 Atr=e0 MxPwr=0mA
I: If#= 0 Alt= 0 #EPs= 1 Cls=09(hub ) Sub=00 Prot=00 Driver=hub
T: Bus=01 Lev=01 Prnt=01 Port=02 Cnt=01 Dev#= 2 Spd=480 MxCh= 0
D: Ver= 2.00 Cls=00(>ifc ) Sub=00 Prot=00 MxPS=64 #Cfgs= 1
P: Vendor=0bc2 ProdID=5021 Rev=01.48
S: Manufacturer=Seagate
S: Product=FreeAgent GoFlex
S: SerialNumber=NA01ZA6B
C: #Ifs= 1 Cfg#= 1 Atr=80 MxPwr=100mA
I: If#= 0 Alt= 0 #EPs= 2 Cls=08(stor.) Sub=06 Prot=50 Driver=usb-storage
T: Bus=02 Lev=00 Prnt=00 Port=00 Cnt=00 Dev#= 1 Spd=12 MxCh= 3
D: Ver= 1.10 Cls=09(hub ) Sub=00 Prot=00 MxPS=64 #Cfgs= 1
P: Vendor=1d6b ProdID=0001 Rev=02.06
S: Manufacturer=Linux 2.6.32-5-686 ohci_hcd
S: Product=OHCI Host Controller
S: SerialNumber=0000:00:02.0
C: #Ifs= 1 Cfg#= 1 Atr=e0 MxPwr=0mA
I: If#= 0 Alt= 0 #EPs= 1 Cls=09(hub ) Sub=00 Prot=00 Driver=hub
T: Bus=03 Lev=00 Prnt=00 Port=00 Cnt=00 Dev#= 1 Spd=12 MxCh= 3
D: Ver= 1.10 Cls=09(hub ) Sub=00 Prot=00 MxPS=64 #Cfgs= 1
P: Vendor=1d6b ProdID=0001 Rev=02.06
S: Manufacturer=Linux 2.6.32-5-686 ohci_hcd
S: Product=OHCI Host Controller
S: SerialNumber=0000:00:02.1
C: #Ifs= 1 Cfg#= 1 Atr=e0 MxPwr=0mA
I: If#= 0 Alt= 0 #EPs= 1 Cls=09(hub ) Sub=00 Prot=00 Driver=hub
The above output gives the information for Bus01,Bus02,Bus03.
If we observe the second set of output for Bus01 we can see that it gives us details of a USB device whose manufacturer is Seagate. The product name is FreeAgent Goflex and the Vendor id is 0bc2 the product id is 5021. (The specific output is made into bold only for reference).
The other buses do not have any device connected hence it only gives information of the bus, and the manufacturer by default is set to linux.
Workqueue-3 using Runtime creation
In the last post we looked into creation of workqueue using static creation method. Let us look at creation using dynaminc creation i.e. using INIT_WORK.
The below call creates a workqueue by the name workq and the function that gets scheduled in the queue is work_fn.
INIT_WORK(workq,workq_fn)
But as this has to be done dynamically we will have to allocate memory for the wrokqueue structure,before creating the workqueue, which can be done using kmalloc as below
workq = kmalloc(sizeof(struct work_struct),GFP_KERNEL);
We can put these in the init function so that the workqueue gets crated as soon as the module is inserted.
In the work_fn we will just add a print statement, but in real modules any thing can be scheduled in the function.
void workq_fn(unsigned long arg)
{
long c;
atomic_long_set(&(workq->data),10);
printk(KERN_INFO "In workq function %u",atomic_long_read(&(workq->data)));
}
Now to schedule the function we will implement the schedule function in the proc entry as
given below.
int sched_workq(char *buf,char **start,off_t offset,int len,int *eof,void *arg)
{
printk(KERN_INFO " In proc sched workq");
schedule_work(workq);
return 0;
}
The init function will have the calls to creation of proc entry and creation of the the workqueue.
int st_init(void)
{
create_proc_read_entry("sched_workq",0,NULL,sched_workq,NULL);
workq = kmalloc(sizeof(struct work_struct ),GFP_KERNEL);
INIT_WORK(workq,workq_fn);
return 0;
}
The exit function will only have removal of the proc entry
void st_exit(void)
{
remove_proc_entry("sched_workq",NULL);
}
Putting all the above together the module will look as follows
**********************workq_runtime.c*********************
#include<linux/kernel.h>
#include<linux/module.h>
#include<linux/init.h>
#include<linux/proc_fs.h> //Required for creating proc entries.
#include<linux/sched.h>
#include <linux/workqueue.h> // Required for workqueues
static struct work_struct *workq;
void workq_fn(unsigned long arg)
{
long c;
atomic_long_set(&(workq->data),10);
printk(KERN_INFO "In workq function %u",atomic_long_read(&(workq->data)));
}
int sched_workq(char *buf,char **start,off_t offset,int len,int *eof,void *arg)
{
printk(KERN_INFO " In proc sched workq");
schedule_work(workq);
return 0;
}
int st_init(void)
{
create_proc_read_entry("sched_workq",0,NULL,sched_workq,NULL);
workq = kmalloc(sizeof(struct work_struct ),GFP_KERNEL);
INIT_WORK(workq,workq_fn);
return 0;
}
void st_exit(void)
{
remove_proc_entry("sched_workq",NULL);
}
module_init(st_init);
module_exit(st_exit);
******************************************************
Save the above code as workq_runtime.c
The makefile required for compilation is
*****************Makefile****************************
ifneq ($(KERNELRELEASE),)
obj-m := workq_runtime.o
else
KERNELDIR ?= /lib/modules/$(shell uname -r)/build
PWD := $(shell pwd)
default:
$(MAKE) -C $(KERNELDIR) M=$(PWD) modules
clean:
$(MAKE) -C $(KERNELDIR) M=$(PWD) clean
endif
**************************************************
Compile and run the code as follows
$ make
If there are no errors then continued
$ insmod worq_runtime.ko
$ cat /proc/sched_work
$ dmesg | tail -5
In proc sched workq
In workq function 10
The above two lines inform us that once the proc entry is read, the function gets scheduled and if the processor is free it gets executed immediately .
Note : We have used a special function "atomi_set" to assign value to variable data in work_struct because the data is of type atomic_long_t and not simple int.
Workqueue-2 DECLARE_WORK
Last post we say the basics of workqueue and different ways to create a workqueue.
Let us now look at an example module to create a workqueue and schedule it.
We will create a workqueue using static creation , i.e. DECLARE_WORK and then look at the runtime creation in the next post.
The below call creates a workqueue by the name workq and the function that gets scheduled in the queue is work_fn.
DECLARE_WORK(workq,workq_fn);
We will just add a print in the work_fn function but in real workqueues this function can be used to carry out any operations that need to be scheduled.
Our work_fn will look as follows
.
void workq_fn(unsigned long arg)
{
long c;
atomic_long_set(&(workq.data),10); //Setting the data field of work_struct.
printk(KERN_INFO "In workq function %u",atomic_long_read(&(workq.data)));
}
For this function to be executed we need to schedule the workqueue which we will implement in a proc entry such that the workqueue gets scheduled when the proc entry is read.
Let us call the proc entry as sched_work, which will be as follows
int sched_workq(char *buf,char **start,off_t offset,int len,int *eof,void *arg)
{
printk(KERN_INFO " In proc sched workq");
schedule_work(&workq);
return 0;
}
The init and exit functions only need to create and remove the proc entries respectively.
int st_init(void)
{
create_proc_read_entry("sched_workq",0,NULL,sched_workq,NULL);
return 0;
}
void st_exit(void)
{
remove_proc_entry("sched_workq",NULL);
}
Putting all the codes together the module will be
*********************workq_static.c*******************************
#include<linux/kernel.h>
#include<linux/module.h>
#include<linux/init.h>
#include<linux/proc_fs.h> //Required for creating proc entries.
#include<linux/sched.h>
#include <linux/workqueue.h> // Required for workqueues
void workq_fn(unsigned long);
DECLARE_WORK(workq,workq_fn);
void workq_fn(unsigned long arg)
{
long c;
atomic_long_set(&(workq.data),10);
printk(KERN_INFO "In workq function %u",atomic_long_read(&(workq.data)));
}
int sched_workq(char *buf,char **start,off_t offset,int len,int *eof,void *arg)
{
printk(KERN_INFO " In proc sched workq");
schedule_work(&workq);
return 0;
}
int st_init(void)
{
create_proc_read_entry("sched_workq",0,NULL,sched_workq,NULL);
return 0;
}
void st_exit(void)
{
remove_proc_entry("sched_workq",NULL);
}
module_init(st_init);
module_exit(st_exit);
*****************************************************************
Save the above code as workq_stati.c . The makefile required for the compiling this will be
*************Makefile***************************
ifneq ($(KERNELRELEASE),)
obj-m := workq_static.o
else
KERNELDIR ?= /lib/modules/$(shell uname -r)/build
PWD := $(shell pwd)
default:
$(MAKE) -C $(KERNELDIR) M=$(PWD) modules
clean:
$(MAKE) -C $(KERNELDIR) M=$(PWD) clean
endif
***************************************************
Compile and test the code as follows
$ make
If there are no errors then continued
$ insmod worq_static.ko
$ cat /proc/sched_work
$ dmesg | tail -5
In proc sched workq
In workq function 10
The above two lines inform us that once the proc entry is read, the function gets scheduled and if the processor is free it gets executed immediately .
Note : We have used a special function "atomi_set" to assign value to variable data in work_struct because the data is of type atomic_long_t and not simple int.
Workqueues-1 Introduction
workqueues, like tasklets, are useful to schedule a task that for future. One of the
main areas where it is used is in scheduling the bottom half of an interrupt service routine.
One of the major differences between a tasklet and a workqueue, though both are used for similar purposes, is that a tasklet works in interrupt context where as a workqueue executes in a process context.
We will look into the differences between tasklet and workqueues in detail in another post.
In this post let us look at how to create a work queue and how to schedule it.
The work_queue are maintained in a structure work_struct, defined in workqueue.h.
The main members of the structure are
atomic_long_t data : The data that will be used by the function that is scheduled by this workqueue.
work_func_t func : The function that has is scheduled by the workqueue.
The workqueues can be implemented in two ways
1. Using the default event threads :The kernel provides default threads called event threads, one per processor, which can be used to schedule the deferred functions of the workqueues. This is simpler as we need not create a new thread and only need to queue up the function for execution. It is advantageous when the amount of work to be done by the deferred function is less
and is not a very strict constraints on the performance.
2. Creating a separate worker thread for the workqueue. Instead of using the default event threads, we can also create separate threads for the functions that have to be deferred as part of the workqueue. Generally separate worker threads are used only when amount of work the function to be deferred is huge which might affect the other workqueues scheduled on the default event thread.
Let us firs look at creating a workqueue using the default event thread.
Creation :
Static creation :
DECLARE_WORK(name, void (*func)(void *))
name: The name of the "work_struct" structure that has to be created.
func: The function to be scheduled in this workqueue.
Creating in runtime
INIT_WORK(struct work_struct *work, void (*func)(void *))
work: The work_struct structure that has to be created.
func: The function to be scheduled in this workqueue.
The prototype of function that has to be scheduled is
void func(void *data)
As the workqueue executes in a process context this function is allowed sleep as well as use semaphores.
Scheduling
schedule_work(&work);
The work gets scheduled as soon as the above call to schedule_work is made, and the function gets executed when the events thread wakes up on the processor on which it is scheduled.
The scheduling can be delayed using the function
schedule_delayed_work(&work, delay);
Where the delay is mentioned in the timer ticks (jiffies).
Flushing all the works :
void flush_scheduled_work(void);
The above call makes sure that all the functions that have been scheduled are executed and returns only after that. One of the applications of the function is while removing the module.
Before removing a module it should be made sure that all the functions deferred for execution by the module are finished which can be achieved by using the above function.
A workqueue can also be canceled using
int cancel_delayed_work(struct work_struct *work);
The next post we will look at creation of workqueue using the static creation.
Tasklets -3 Using Macros
In the last two posts we learnt about the tasklets and creating them dynmically using taslet_init.
In this post let us look at an example module that will create a tasklet using the macros
DECLARE_TASKLET and DECLARE_TASKLET_DISABLED.
We use the macros as follows
DECLARE_TASKLET_DISABLED(task_dis,task_fn, 1);
task_dis is the name of the tasklet, task_fn is the function to be executed as part of the tasklet and we are passing "1" as data to the function. By default this tasklet will be disabled and will need to be enabled.
DECLARE_TASKLET(task_en,task_fn, 2);
task_en is the name of the tasklet, task_fn is the function to be executed as part of the tasklet and we are passing "2" as data to the function. By default the tasklet will be enabled and only needs to be scheduled.
We create two proc entries,
enabtask: To enable the tasklet that has started out disabled. We will print the value of the count to see the difference between the two tasklets .
schedtask: To schedule the tasklets that have been enabled. You can not schedule a tasklet that has not been enabled.
The proc entry function will look as follows
int enabtask(char *buf,char **start,off_t offset,int len,int *eof,void *arg)
{
printk(KERN_INFO " In proc enabtask");
printk(KERN_INFO "\n The state of disabled task is %d and count is %d ",task_dis.state,task_dis.count);
printk(KERN_INFO "\n The state of enabled task is %d and count is %d ",task_en.state,task_en.count);
tasklet_enable(&task_dis);
return 0;
}
int schedtask(char *buf,char **start,off_t offset,int len,int *eof,void *arg)
{
printk(KERN_INFO " In proc schedtask");
tasklet_schedule(&task_dis);
tasklet_schedule(&task_en);
printk(KERN_INFO "\n The state of disabled task is %d and count is %d ",task_dis.state,task_dis.count);
printk(KERN_INFO "\n The state of enabled task is %d and count is %d ",task_en.state,task_en.count);
return 0;
}
Note: To learn more about proc entries please see "Proc Entries" in this page "Kernel Programming"
In the task_fn, which will be executed as part of the tasklet we will also print the data that has been passed to differentiated between the tasklets.
void task_fn(unsigned long arg)
{
printk(KERN_INFO "In tasklet function %u" ,arg);
}
The init and exit functions are similar to the previous example
int st_init(void)
{
create_proc_read_entry("enabask",0,NULL,enabtask,NULL);
create_proc_read_entry("schedtask",0,NULL,schedtask,NULL);
return 0;
}
void st_exit(void)
{
remove_proc_entry("enabask",NULL);
remove_proc_entry("schedtask",NULL);
}
Putting the code together the module will look as follows
************************tasklet_macro.c****************************
#include<linux/kernel.h>
#include<linux/module.h>
#include<linux/init.h>
#include<linux/proc_fs.h>
#include<linux/sched.h>
#include <linux/interrupt.h>
void task_fn(unsigned long arg)
{
printk(KERN_INFO "In tasklet function %u" ,arg);
}
DECLARE_TASKLET_DISABLED(task_dis,task_fn, 1);
DECLARE_TASKLET(task_en,task_fn, 2);
int enabtask(char *buf,char **start,off_t offset,int len,int *eof,void *arg)
{
printk(KERN_INFO " In proc enabtask");
printk(KERN_INFO "\n The state of disabled task is %d and count is %d ",task_dis.state,task_dis.count);
printk(KERN_INFO "\n The state of enabled task is %d and count is %d ",task_en.state,task_en.count);
tasklet_enable(&task_dis);
return 0;
}
int schedtask(char *buf,char **start,off_t offset,int len,int *eof,void *arg)
{
printk(KERN_INFO " In proc schedtask");
tasklet_schedule(&task_dis);
tasklet_schedule(&task_en);
printk(KERN_INFO "\n The state of disabled task is %d and count is %d ",task_dis.state,task_dis.count);
printk(KERN_INFO "\n The state of enabled task is %d and count is %d ",task_en.state,task_en.count);
return 0;
}
int st_init(void)
{
create_proc_read_entry("enabask",0,NULL,enabtask,NULL);
create_proc_read_entry("schedtask",0,NULL,schedtask,NULL);
return 0;
}
void st_exit(void)
{
remove_proc_entry("enabask",NULL);
remove_proc_entry("schedtask",NULL);
}
module_init(st_init);
module_exit(st_exit);
*********************************************************************************
Save the code as tasklet_macro.c
Makefile needed for the module is
*************************Makefile*********************************
ifneq ($(KERNELRELEASE),)
obj-m := tasklet_macro.o
else
KERNELDIR ?= /lib/modules/$(shell uname -r)/build
PWD := $(shell pwd)
default:
$(MAKE) -C $(KERNELDIR) M=$(PWD) modules
clean:
$(MAKE) -C $(KERNELDIR) M=$(PWD) clean
endif
**************************************************************
To compile the test the code run as follows.
$ make
If there are no errors, then continue.
$ insmod tasklet_macro.ko
$ cat /proc/enabtask
$ dmesg
In proc enabtask
The state of disabled task is 0 and count is 1
The state of enabled task is 0 and count is 0
You should see the above three lines of output in the log.
We can see that the state of both tasklets is 0 as neither of them are running .
The count value of disabled tasklet is "1" and that of enabled tasklet is "0".
$ cat /proc/schedtask
In proc schedtask
The state of disabled task is 1 and count is 0
The state of enabled task is 1 and count is 0
In tasklet function 1
In tasklet function 2
From The above messaged we see tha the state of both the tasks have changed from 0 to 1 indicating that they are ready to and the count of the tasks is 0 indicating that both are in enabled state.
The last two lines of the message prints the message present in task_fn and also prints the value of the data that we had passed to the respective tasklets.
Tasklet-2 using tasklet_init
In the previous post we saw the basics of a tasklet, now let us look at an example module that creates a tasklet.
We will use the function "tasklet_init" to create the tasklet in this example.
In this module we will create a read proc entry called "initask". On reading this proc entry a tasklet will get initialized and scheduled.
The function executed on reading the proc etnry will be :
Working :
task = kmalloc(sizeof(struct tasklet_struct),GFP_KERNEL);
This line allocates memory for a new tasklet and returns a pointer to the structure.
tasklet_init(task,task_fn,0);
This initates the tasklet "task" . The function that will be executed as a part of the tasklet is "task_fn" which has to be implemented in the module.
In our "task_fn" we will just print the state and value of count of the tasklet. In real tasklets, it is here that the main work happens.
task_fn:
The init and exit functions are going to be pretty simple as we have nothing much to do in them.
init and exit functions:
Thus the full code of the module with the required header files will look as follows tasklet_init.c
Save the code as tasklet_init.c
The Makefile required for this is
To see the output run the following commands
If there are no errors then continue.
Ouptut:
You shoud see the above lines being printed in the logs.
We scheduled the tasklet when proc entry was read, our processor was not heavily loaded hence the tasklet got scheduled immediately and thus the "task_fn" got executed.
The state "2" signifies the tasklet is running and the count being 0 signifies tasklet is enabled.
We will use the function "tasklet_init" to create the tasklet in this example.
In this module we will create a read proc entry called "initask". On reading this proc entry a tasklet will get initialized and scheduled.
The function executed on reading the proc etnry will be :
Working :
task = kmalloc(sizeof(struct tasklet_struct),GFP_KERNEL);
This line allocates memory for a new tasklet and returns a pointer to the structure.
tasklet_init(task,task_fn,0);
This initates the tasklet "task" . The function that will be executed as a part of the tasklet is "task_fn" which has to be implemented in the module.
In our "task_fn" we will just print the state and value of count of the tasklet. In real tasklets, it is here that the main work happens.
task_fn:
The init and exit functions are going to be pretty simple as we have nothing much to do in them.
init and exit functions:
Thus the full code of the module with the required header files will look as follows tasklet_init.c
Save the code as tasklet_init.c
The Makefile required for this is
To see the output run the following commands
If there are no errors then continue.
Ouptut:
You shoud see the above lines being printed in the logs.
We scheduled the tasklet when proc entry was read, our processor was not heavily loaded hence the tasklet got scheduled immediately and thus the "task_fn" got executed.
The state "2" signifies the tasklet is running and the count being 0 signifies tasklet is enabled.
Tasklets -1 Introduction
Tasklets are used in kernel to schedule a function some time in future. The major use of the tasklet is to schedule the bottom half of an interrupt service routine.
Bottom half is the part of the interrupt service routine which is not time critical and can be executed after a little delay from the time interrupt is generated. This helps is releasing the interrupt line quickly and processing more interrupts.
Let us look at how we can create a tasklet and schedule it in a kernel module.
The structure, tasklet_struct, declared in interrupt.h looks as follows
The members of the structure that has to be initialized in the module are :
func : Pointer to the function that needs to scheduled for execution at a later time
data : Data to be passed to the function "func"
The other three members are initialized by the kernel as follows
"count" holds a nonzero value if the tasklet is disabled and 0 if it is enabled.
states
TASKLET_STATE_SCHED , which denotes it is scheduled to run. TASKLET_STATE_RUN , which denotes it is running.
There are two ways of creating a tasklet
Creating Statically: (using Macros)
DECLARE_TASKLET(name, func, data): Creates a tasklet in the enabled state
DECLARE_TASKLET_DISABLED(name, func, data): Creates a tasklet in the disabled state
If the tasklets is created using the second macro it needs to be enabled explicitly.
Creating in runtime:
tasklet_init(name,func,data)
Where "name" is the name of the taskelet, "func" in the function which has to be executed as a part of the tasklet and "data" is the data that has to passed to func.
Function:Prototype of the function that has to be scheduled by the tasklet is void "function"(unsigned long data)
A tasklet is a softirq and hence runs in an interrupt context. Thus while executing the function you are not allowed to go to sleep and have to use proper locking for any data that is shared with other tasklets.
Scheduling a tasklet:
Once the tasklet has been created, it needs to be scheduled which is done by the function
tasklet_schedule(&tasklet)
Enable and Disable :
The tasklets can be disabled, if they are not running already, using
tasklet_disable(&taskelt)
and enabled using
tasklet_enble(&tasklet)
When does the tasklet actually get scheduled can not be controlled and is decided by the scheduler depending on the load on the processor. If the processor is free, it might get scheduled immediately.
In the next two posts we will look at example code of creating tasklet statically and dynamically.
Tasklets-2 tasklet_init Tasklets-3 Using Macros
Bottom half is the part of the interrupt service routine which is not time critical and can be executed after a little delay from the time interrupt is generated. This helps is releasing the interrupt line quickly and processing more interrupts.
Let us look at how we can create a tasklet and schedule it in a kernel module.
The structure, tasklet_struct, declared in interrupt.h looks as follows
The members of the structure that has to be initialized in the module are :
func : Pointer to the function that needs to scheduled for execution at a later time
data : Data to be passed to the function "func"
The other three members are initialized by the kernel as follows
"count" holds a nonzero value if the tasklet is disabled and 0 if it is enabled.
states
TASKLET_STATE_SCHED , which denotes it is scheduled to run. TASKLET_STATE_RUN , which denotes it is running.
There are two ways of creating a tasklet
Creating Statically: (using Macros)
DECLARE_TASKLET(name, func, data): Creates a tasklet in the enabled state
DECLARE_TASKLET_DISABLED(name, func, data): Creates a tasklet in the disabled state
If the tasklets is created using the second macro it needs to be enabled explicitly.
Creating in runtime:
tasklet_init(name,func,data)
Where "name" is the name of the taskelet, "func" in the function which has to be executed as a part of the tasklet and "data" is the data that has to passed to func.
Function:Prototype of the function that has to be scheduled by the tasklet is void "function"(unsigned long data)
A tasklet is a softirq and hence runs in an interrupt context. Thus while executing the function you are not allowed to go to sleep and have to use proper locking for any data that is shared with other tasklets.
Scheduling a tasklet:
Once the tasklet has been created, it needs to be scheduled which is done by the function
tasklet_schedule(&tasklet)
Enable and Disable :
The tasklets can be disabled, if they are not running already, using
tasklet_disable(&taskelt)
and enabled using
tasklet_enble(&tasklet)
When does the tasklet actually get scheduled can not be controlled and is decided by the scheduler depending on the load on the processor. If the processor is free, it might get scheduled immediately.
In the next two posts we will look at example code of creating tasklet statically and dynamically.
Tasklets-2 tasklet_init Tasklets-3 Using Macros
To kill a process after specific duration
If you want to make sure that a certain process or application runs exactly for a given duration and gets kill automatically after that, then the command timeout will help.
Let us say we want to run google-chrome for only a minute and then kill it, then we can do the following
$ timeout 1m google-chrome
1m specifies 1 minute, similarly you can use the suffix "s" for seconds and suffix "d" for days.
As a result of the above command, google-chrome will launch and will get killed automatically at the end of 1 minute from the time the command was run.
Enabling capslock from command line
setleds : Command to set the keyboard leds like capslock, numlock etc.
If you want to turn on the "capslock" or the "numlock" from the command line you can use this command.
For eg to turn on the caps lock run the following
Note: You will have to be in text mode to run the command,it does not run in graphics mode
$ setleds +caps
You should see the capslock led turn on and any thing you type will be in capital. You can turn the capital off by using the caps lock key on the keyboard but the led of caps lock will continue to glow.
To turn the led off run
$ setleds -caps
The same is valid for num lock using the keyword "num" and for scroll lock using the keyword "scroll".
If you want to turn on the "capslock" or the "numlock" from the command line you can use this command.
For eg to turn on the caps lock run the following
Note: You will have to be in text mode to run the command,it does not run in graphics mode
$ setleds +caps
You should see the capslock led turn on and any thing you type will be in capital. You can turn the capital off by using the caps lock key on the keyboard but the led of caps lock will continue to glow.
To turn the led off run
$ setleds -caps
The same is valid for num lock using the keyword "num" and for scroll lock using the keyword "scroll".
Script to check for palindrome using "rev"
The command "rev" reverses the lines of the file given to it as input. we can use this command to find out whether a given string is palindrome or no.
A palindrome is any string that appears the same when read from left to right or right to left.
For Eg:
mom : will be same if we read it left to right or right to left, hence it is a palindrome.
tree: will be read as eert if read from right to left which is different from tree hence the string is not a palindrome.
The command rev takes the lines of file given as input and prints them in reverse.
For eg:
If we have a file named "one" with contents "The weather has been cloudy "
$ rev one
yduolc neeb sah rehtaew ehT
A palindrome is any string that appears the same when read from left to right or right to left.
For Eg:
mom : will be same if we read it left to right or right to left, hence it is a palindrome.
tree: will be read as eert if read from right to left which is different from tree hence the string is not a palindrome.
The command rev takes the lines of file given as input and prints them in reverse.
For eg:
If we have a file named "one" with contents "The weather has been cloudy "
$ rev one
yduolc neeb sah rehtaew ehT
As we see rev prints the line from right to left.
Now let us try to write a script that will use "rev" to find out if a given string is a palindrome or not.
Note: The script creates and new file by the name temp in the present working directory and deletes it . In case you have any other file by the name temp, it will get overwritten and deleted if you do not rename it or modify the script.
#! /bin/bash
if [ $# -le 2 ] # if word is not passed in command line, take it as input.
then
echo "Enter the word"
read input # Store the word in variable input
fi
echo $input > temp # Write the input into a temporary file.
reverse=`rev temp` # Run the command rev on the temporary file . store result in another variable
echo $reverse
if [ $input==$reverse ] #Compare the input and reversed string.
then
echo "it is a palindrome"
else
echo "Not a palindrome"
fi
rm temp # Remove the temporary file created.
Working directory of a process
If you want to find from which directory was a process launched or which directory is a process running from you can use the command "pwdx"
It takes as input the process id of the process of which you want to find the directory.
For eg:
$ sudo pwdx 1
/
The pid one belongs to "init" and it is run from the root directory "/" .
You can use the command "ps -ef" or "pidof" to find the pid of the process you are interested in.
It takes as input the process id of the process of which you want to find the directory.
You will have to run the command as root.
For eg:
$ sudo pwdx 1
/
The pid one belongs to "init" and it is run from the root directory "/" .
You can use the command "ps -ef" or "pidof" to find the pid of the process you are interested in.
Determine are you running on battery through command prompt
If you are running in the text mode and want to find out if your laptop is running on battery or on ac power you can use the command "on_ac_power".
The command returns "0" if laptop is running on ac power, 1 if it is runnning on battery and 255 if it can not determine.
For eg:
$ ac_on_power
$ echo $?
0
Thus the laptop is running on ac power.
You can use the following script to make the output look more user friendly.
#!/bin/bash
on_ac_power
if [ $? -eq 0 ]
then
echo "Running on ac power"
elif [ $? -eq 1 ]
then
echo "Running on Battery"
else
echo "Can not detemine"
fi
Save the script as power.sh and run it as follows.
$ sh power.sh
Running on ac power
Thus giving the required information in more readable format.
PangoRendererClass' has no member named 'draw_glyph_item' : update tango
PangoRendererClass' has no member named 'draw_glyph_item'
Hit the above error while compiling gtk+ version 3.0.
The problem was with the pango version, got the error when pango version was 1.20.
But the error did not appear after updating pango to 1.28.
Hit the above error while compiling gtk+ version 3.0.
The problem was with the pango version, got the error when pango version was 1.20.
But the error did not appear after updating pango to 1.28.
All fonts in gnome turn into square symbols
This is a problem encountered while installing gtk+. After installing all of the packages required to install gtk+ and a system reboot all the characters in filenames, menu etc had turned into just square symbols. None of the fonts were visible.
The culprit was the package "pango" which is required for gtk+. To get back the usual display it was required to unistall pango which can be done from the same folder from which it was installed from source.
cd to the folder that has source of pango
$ sudo make uninstall
$sudo reboot
After reboot all the fonts were back :-)
The culprit was the package "pango" which is required for gtk+. To get back the usual display it was required to unistall pango which can be done from the same folder from which it was installed from source.
cd to the folder that has source of pango
$ sudo make uninstall
$sudo reboot
After reboot all the fonts were back :-)
configure: error:
*** Checks for TIFF loader failed. You can build without it by passing
*** --without-libtiff to configure but some programs using GTK+ may
*** not work properly
If you hit the above error while configuring gdk-pixbuf or any other package while installing gtk+, the workaround is
to install libtiff4-dev
$ sudo apt-get install libtiff4-dev
*** Checks for TIFF loader failed. You can build without it by passing
*** --without-libtiff to configure but some programs using GTK+ may
*** not work properly
If you hit the above error while configuring gdk-pixbuf or any other package while installing gtk+, the workaround is
to install libtiff4-dev
$ sudo apt-get install libtiff4-dev
Error while configuring Gdk-pixbuf for gtk
The following error might appear while configuring Gdk-pixbuf which is needed for installing Gtk.
checking for GLIB - version >= 2.25.15...
*** 'pkg-config --modversion glib-2.0' returned 2.29.12, but GLIB (2.24.2)
*** was found! If pkg-config was correct, then it is best
*** to remove the old version of GLib. You may also be able to fix the error
*** by modifying your LD_LIBRARY_PATH enviroment variable, or by editing
*** /etc/ld.so.conf. Make sure you have run ldconfig if that is
*** required on your system.
*** If pkg-config was wrong, set the environment variable PKG_CONFIG_PATH
*** to point to the correct configuration files
no
configure: error:
*** GLIB 2.25.15 or better is required. The latest version of
*** GLIB is always available from ftp://ftp.gtk.org/pub/gtk/
The error could be because of multiple versions of glib versions present in your system.
Workaround:
Look at the contents of "/lib"
$ ls -l libg*
-rw-r--r-- 1 root root 116600 Nov 14 2010 libgcc_s.so.1
lrwxrwxrwx 1 root root 23 Jul 11 14:00 libglib-2.0.so.0 -> libglib-2.0.so.0.2400.2
lrwxrwxrwx 1 root root 23 Jul 11 14:00 libglib-2.0.so.0.2400.2
If the output is some thing similar to the above ,we can see that the lib file present in the /lib is of 2.24 version which is being detected while configuring. To change this we need to locate the newer ".so" file.
Run the following commands to locate if a newer file is present.
$sudo updatedb
$sudo locate libglib-2.so.0
/lib/libglib-2.0.so.0
/lib/libglib-2.0.so.0.2400.2
/usr/local/lib/libglib-2.0.so.0
/usr/local/lib/libglib-2.0.so.0.2912.0
/usr/local/share/gdb/auto-load/libglib-2.0.so.0.2912.0-gdb.py
In the output we can see that the newer, 2.29.12, is present ins "/usr/local/lib/" i.e. /usr/local/lib/libglib-2.0.so.0.2912.0.
So we need to remove the older lib file in /lib and replace it with this new one. Which can be done as follows
$ sudo rm /lib/libglib-2.0.so.0.2400.2
$ sudo rm /lib/libglib-2.0.so.0
$ sudo cp /usr/local/lib/libglib-2.0.so.0.2912.0
$ sudo ln -s /usr/local/lib/libglib-2.0.so.0.2912.0 /lib/libglib-2.0.so.0
Now run the configure again and your error should not appear again.
Also remove all the previous libglib files from /usr/local/lib, i.e. in this case /lib/libglib-2.0.so.0.2400.2.
nm : Command to list the symbols in object files.
If you want to peep into an object file, and see what are the various symbols that are defines in it the command will come handy.
It takes an object file as input and lists out all the symbols, their address and in which section, text,data,uninitialized etc, is the symbol present in as the output.
For example let us assume we have an object file "hello.o" for the simple hello world program hello.c.
#include<stdio.h>
main()
{
printf("Hello world");
}
Running "nm" on the hello.o will yield
$nm hello.o
00000000 T main
U printf
T before "main" signifies it is in the text section and the "U" before printf means it is undefined in this code. The first column gives the value of the symbol.
It takes an object file as input and lists out all the symbols, their address and in which section, text,data,uninitialized etc, is the symbol present in as the output.
For example let us assume we have an object file "hello.o" for the simple hello world program hello.c.
#include<stdio.h>
main()
{
printf("Hello world");
}
Running "nm" on the hello.o will yield
$nm hello.o
00000000 T main
U printf
T before "main" signifies it is in the text section and the "U" before printf means it is undefined in this code. The first column gives the value of the symbol.
namei : A command to follow pathnames
namei
The command takes as input a path or a file/directory gives, as output, information about the file and also about the other directories in the path. If the input is a symbolic link, it will follow the link to the original file showing the path that needs to be taken to reach the original file.
For eg if we have a folder "temp" with the files one,two and three then command namei on a file can be run as follows
$ namei /home/user/Desktop/temp/one
f: /home/user/Desktop/temp/one
d /
d home
d user
d Desktop
d temp
- one
In the output above the "d" in the first column informs us that the item in second column is a directory and the "-" informs that the item in second column is simple text file, thus giving us information about all the directories that lead up to the file we are interested in.
The -o option that will give information about the owners of the all the folders along the path as shown below.
$ namei -o /home/user/Desktop/temp/one
f: /home/user/Desktop/temp/one
d root root /
d root root home
d user adm nitin
d user adm Desktop
d user root temp
- user root one
If the file passed as the argument is a symbolic link then command will follow till the real file.
For Eg Assume that the file "two" in our example is a link to another file "four" in the Desktop.
$ namei /home/user/Desktop/temp/two
f: /home/user/Desktop/temp/two
d root root /
d root root home
d user adm nitin
d user adm Desktop
d user root temp
l user root two -> ../four
d user root ..
- root root four
The letter "l" in the first column indicates the the file is a symbolic link, and then the entries after that is the relative path from the link to the original file.
The option -l gives output similar to "ls -l" and the option "-m" gives the permission of each file or folder.
The command takes as input a path or a file/directory gives, as output, information about the file and also about the other directories in the path. If the input is a symbolic link, it will follow the link to the original file showing the path that needs to be taken to reach the original file.
For eg if we have a folder "temp" with the files one,two and three then command namei on a file can be run as follows
$ namei /home/user/Desktop/temp/one
f: /home/user/Desktop/temp/one
d /
d home
d user
d Desktop
d temp
- one
In the output above the "d" in the first column informs us that the item in second column is a directory and the "-" informs that the item in second column is simple text file, thus giving us information about all the directories that lead up to the file we are interested in.
The -o option that will give information about the owners of the all the folders along the path as shown below.
$ namei -o /home/user/Desktop/temp/one
f: /home/user/Desktop/temp/one
d root root /
d root root home
d user adm nitin
d user adm Desktop
d user root temp
- user root one
If the file passed as the argument is a symbolic link then command will follow till the real file.
For Eg Assume that the file "two" in our example is a link to another file "four" in the Desktop.
$ namei /home/user/Desktop/temp/two
f: /home/user/Desktop/temp/two
d root root /
d root root home
d user adm nitin
d user adm Desktop
d user root temp
l user root two -> ../four
d user root ..
- root root four
The letter "l" in the first column indicates the the file is a symbolic link, and then the entries after that is the relative path from the link to the original file.
The option -l gives output similar to "ls -l" and the option "-m" gives the permission of each file or folder.
Listing CPU details
If you want to know the details of the processor in your system, there are two ways to the information.
First is by looking into /proc/cpuinfo, this gives a lot of details, including the vendor name, the frequency,L2 or l3 cache size etc.
For eg:
$ cat /proc/cpuoinfo
processor : 0
vendor_id : AuthenticAMD
cpu family : 15
model : 12
model name : AMD Athlon(tm) XP Processor 3000+
stepping : 0
cpu MHz : 800.000
cache size : 256 KB
fdiv_bug : no
hlt_bug : no
f00f_bug : no
coma_bug : no
fpu : yes
fpu_exception : yes
cpuid level : 1
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 syscall nx mmxext 3dnowext 3dnow up
bogomips : 1595.97
clflush size : 64
cache_alignment : 64
address sizes : 40 bits physical, 32 bits virtual
power management: ts fid vid ttp
Another way is by running the command "lscpu". This gives lesser information than the proc entry above but has some information not available in the output of cpuinfo, like the architecture, the L1 cache details etc.
For eg:
$ lscpu
Architecture: i686
CPU(s): 1
Thread(s) per core: 1
Core(s) per socket: 1
CPU socket(s): 1
Vendor ID: AuthenticAMD
CPU family: 15
Model: 12
Stepping: 0
CPU MHz: 800.000
L1d cache: 64K
L1i cache: 64K
L2 cache: 256K
First is by looking into /proc/cpuinfo, this gives a lot of details, including the vendor name, the frequency,L2 or l3 cache size etc.
For eg:
$ cat /proc/cpuoinfo
processor : 0
vendor_id : AuthenticAMD
cpu family : 15
model : 12
model name : AMD Athlon(tm) XP Processor 3000+
stepping : 0
cpu MHz : 800.000
cache size : 256 KB
fdiv_bug : no
hlt_bug : no
f00f_bug : no
coma_bug : no
fpu : yes
fpu_exception : yes
cpuid level : 1
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 syscall nx mmxext 3dnowext 3dnow up
bogomips : 1595.97
clflush size : 64
cache_alignment : 64
address sizes : 40 bits physical, 32 bits virtual
power management: ts fid vid ttp
Another way is by running the command "lscpu". This gives lesser information than the proc entry above but has some information not available in the output of cpuinfo, like the architecture, the L1 cache details etc.
For eg:
$ lscpu
Architecture: i686
CPU(s): 1
Thread(s) per core: 1
Core(s) per socket: 1
CPU socket(s): 1
Vendor ID: AuthenticAMD
CPU family: 15
Model: 12
Stepping: 0
CPU MHz: 800.000
L1d cache: 64K
L1i cache: 64K
L2 cache: 256K
lsinitramfs: Listing the contents of the initrd file system.
The initramfs is a very basic kernel, which helps boot the full kernel . By defaul the initramfs is a gzip compressed file and one can not directly look into it without unzipping it.
lsinitramfs is a command that lists the contents of the initramfs/initrd file with out unzipping it. It only gives a list of the files and can not help in look into the contents of the file.
For rg:
$ lsinitramfs /boot/initrd.img-2.6.32
/boot/initrd.img-2.6.32
.
bin
bin/reboot
bin/readlink
bin/sleep
bin/wget
bin/busybox
bin/dd
bin/live-preseed
bin/insmod
bin/live-reconfigure
bin/gunzip
bin/kill
bin/ipconfig
bin/nfsmount
bin/run-init
bin/eject
bin/mknod
bin/losetup
bin/sh
bin/pivot_root
bin/mkdir
bin/cat
bin/sh.shared
bin/minips
bin/fstype
bin/nuke
bin/umount
bin/cpio
bin/resume
bin/sync
bin/dmesg
bin/ls
bin/gzip
bin/ln
bin/false
bin/chroot
bin/mount
bin/true
bin/mkfifo
bin/halt
bin/poweroff
bin/rsync
bin/md5sum
bin/uname
sbin
sbin/modprobe
sbin/dmsetup
sbin/blockdev
sbin/losetup
sbin/blkid
sbin/udevadm
sbin/udevd
sbin/rmmod
etc
etc/modprobe.d
etc/modprobe.d/linux-sound-base_noOSS.conf
etc/modprobe.d/i915-kms.conf
etc/modprobe.d/fbdev-blacklist.conf
etc/modprobe.d/aliases.conf
etc/modprobe.d/alsa-base.conf
etc/modprobe.d/alsa-base-blacklist.conf
etc/modprobe.d/radeon-kms.conf
etc/modprobe.d/blacklist.conf
etc/udev
etc/udev/udev.conf
lib
lib/libacl.so.1.1.0
lib/libattr.so.1.1.0
lib/libpopt.so.0
lib/ld-linux.so.2
lib/libpthread.so.0
lib/libuuid.so.1
lib/libblkid.so.1
lib/libm.so.6
lib/live-boot
lib/modules
lib/modules/2.6.32
lib/modules/2.6.32/modules.alias.bin
lib/modules/2.6.32/modules.dep
lib/modules/2.6.32/modules.softdep
lib/modules/2.6.32/kernel
lib/modules/2.6.32/kernel/drivers
lib/modules/2.6.32/kernel/drivers/scsi
lib/modules/2.6.32/kernel/drivers/scsi/scsi_wait_scan.ko
lib/modules/2.6.32/modules.order
lib/modules/2.6.32/modules.dep.bin
lib/modules/2.6.32/modules.alias
lib/modules/2.6.32/modules.symbols
lib/modules/2.6.32/modules.devname
lib/modules/2.6.32/modules.symbols.bin
lib/klibc-wbwbg7GBhllIGBCTEv0okjVELWk.so
lib/libattr.so.1
lib/udev
lib/udev/input_id
lib/udev/usb_id
lib/udev/rules.d
lib/udev/rules.d/60-persistent-storage-dm.rules
lib/udev/rules.d/50-udev-default.rules
lib/udev/rules.d/80-drivers.rules
lib/udev/rules.d/60-persistent-storage.rules
lib/udev/rules.d/55-dm.rules
lib/udev/rules.d/91-permissions.rules
lib/udev/ata_id
lib/udev/edd_id
lib/udev/scsi_id
lib/udev/cdrom_id
lib/udev/v4l_id
lib/udev/firmware.agent
lib/udev/hotplug.functions
lib/udev/path_id
lib/librt.so.1
lib/libdl.so.2
lib/libudev.so.0
lib/libselinux.so.1
lib/libblkid.so.1.1.0
lib/libuuid.so.1.3.0
lib/libacl.so.1
lib/libc.so.6
lib/libdevmapper.so.1.02.1
init
conf
conf/modules
conf/initramfs.conf
conf/arch.conf
conf/conf.d
conf/conf.d/resume
scripts
scripts/live-functions
scripts/live-premount
scripts/live-premount/readonly
scripts/live-premount/select_eth_device
scripts/live-premount/ORDER
scripts/live-premount/modules
scripts/live-bottom
scripts/live-bottom/24preseed
scripts/live-bottom/12fstab
scripts/live-bottom/ORDER
scripts/live-bottom/30accessibility
scripts/live-bottom/08persistence_excludes
scripts/live-bottom/23networking
scripts/live
scripts/init-top
scripts/init-top/all_generic_ide
scripts/init-top/ORDER
scripts/init-top/udev
scripts/init-top/keymap
scripts/init-top/blacklist
scripts/live-helpers
scripts/local
scripts/init-bottom
scripts/init-bottom/ORDER
scripts/init-bottom/udev
scripts/local-premount
scripts/local-premount/ORDER
scripts/local-premount/resume
scripts/nfs
scripts/functions
usr
usr/lib
usr/lib/libz.so.1
usr/lib/libcrypto.so.0.9.8
usr/lib/libssl.so.0.9.8
usr/share
usr/share/live-boot
usr/share/live-boot/languagelist
We can also view the long listing using the option "-l" with the command.