The address that the CPU sends for a read or a write operation is the address of the main memory. But before accessing the main memory the cache is checked to find if the contents of the main memory for that block have been stored in the cache or not.
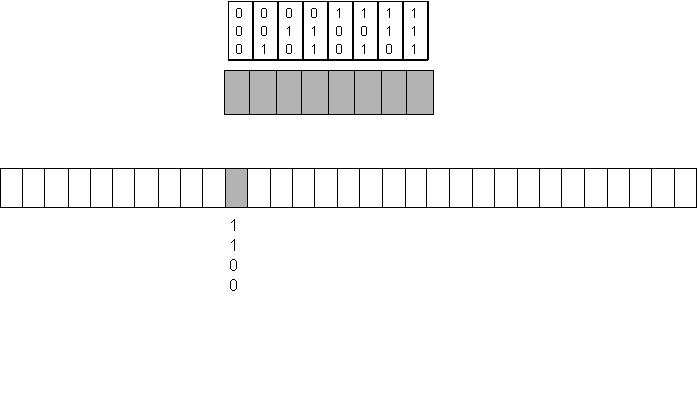
Let us assume a Main memory of 32 blocks, which will need 5 bits to address, and a cache memory of 8 blocks which will need 3 bits to address.
Every block of cache that stores the data also has a field called as the tag filed which holds the MSB of the address of the main memory block which it maps to.
The processor sends a 5 bit address of the main memory for a read operation. Let us say 10110.
This address is split into two parts "index" and the "tag".
Index is the LSB 3 bits , i.e. the n number of bits required to address the cache. These 3 bits point to the block in the cache where data of this memory might reside.
Next the remaining 2 MSB bits are compared with the "tag" field present in the block number of the cache. If the MSB bits match with the tag field of the cache then the data available in the cache is of the main memory block which the processor wants to read.
In our eg Index field is 101 .
The tag field is 10
If the tag field of cache block also has 10 then it is a cache hit, else it is a cache miss. and the data will have to be moved into the cache from the main memory.
The same is depicted in the figure below.
 The above figure shows the working in case of a direct mapped cache. In case of a set associative cache the tags of all the blocks in the cache will have to be compared, and if it matches in any of them then it is a hit.
The above figure shows the working in case of a direct mapped cache. In case of a set associative cache the tags of all the blocks in the cache will have to be compared, and if it matches in any of them then it is a hit.
The Index becomes the set number instead of the block number. The same is depicted in the figure below.

In the case of a fully associative cache as there exits no mapping rule, the cache stores with each block the address of the main memory to which it is mapped to and to figure out if the required memory location is present in the cache or not the whole address needs to be compared, in other words the tag value in the cache value for a fully associative cache is the whole address of the main memory to which it is mapped to. The Working of a fully associative cache is shown below.

The choice of cache mapping affects the number of hits and number of misses. In different scenarios different techniques turn out to he better, with direct mapping being the most rigid of all and the fully associative being the most flexible.
Let us assume a Main memory of 32 blocks, which will need 5 bits to address, and a cache memory of 8 blocks which will need 3 bits to address.
Every block of cache that stores the data also has a field called as the tag filed which holds the MSB of the address of the main memory block which it maps to.
The processor sends a 5 bit address of the main memory for a read operation. Let us say 10110.
This address is split into two parts "index" and the "tag".
Index is the LSB 3 bits , i.e. the n number of bits required to address the cache. These 3 bits point to the block in the cache where data of this memory might reside.
Next the remaining 2 MSB bits are compared with the "tag" field present in the block number of the cache. If the MSB bits match with the tag field of the cache then the data available in the cache is of the main memory block which the processor wants to read.
In our eg Index field is 101 .
The tag field is 10
If the tag field of cache block also has 10 then it is a cache hit, else it is a cache miss. and the data will have to be moved into the cache from the main memory.
The same is depicted in the figure below.

The Index becomes the set number instead of the block number. The same is depicted in the figure below.

In the case of a fully associative cache as there exits no mapping rule, the cache stores with each block the address of the main memory to which it is mapped to and to figure out if the required memory location is present in the cache or not the whole address needs to be compared, in other words the tag value in the cache value for a fully associative cache is the whole address of the main memory to which it is mapped to. The Working of a fully associative cache is shown below.

The choice of cache mapping affects the number of hits and number of misses. In different scenarios different techniques turn out to he better, with direct mapping being the most rigid of all and the fully associative being the most flexible.